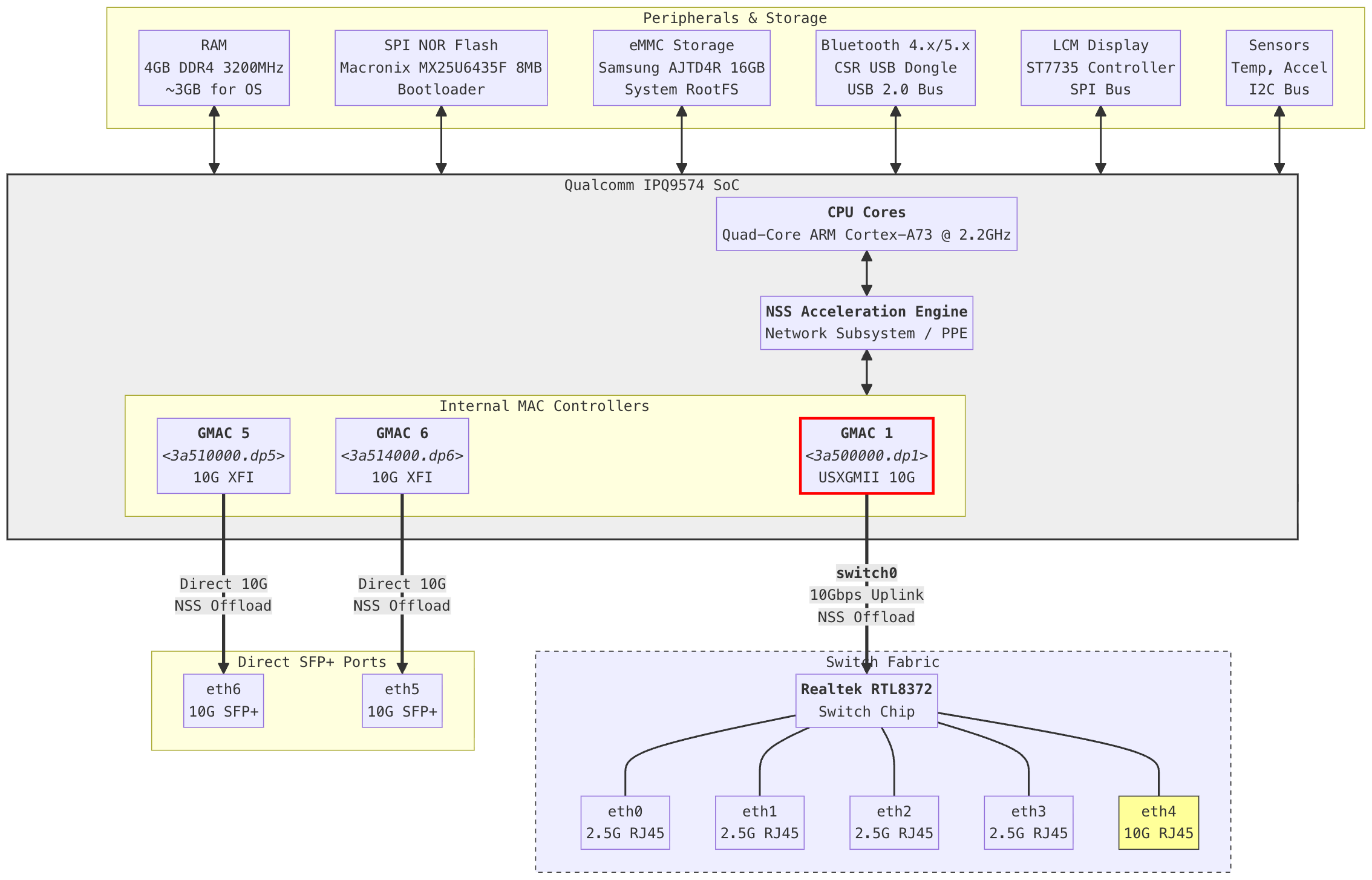
免责声明:我只是为了在自建的云游戏串流虚拟机上进行远程游戏,用虚拟机是因为All-in-boom宿主机还要跑别的东西。请勿用于非法用途,当然对于非法用途的人也早就知道这些了。
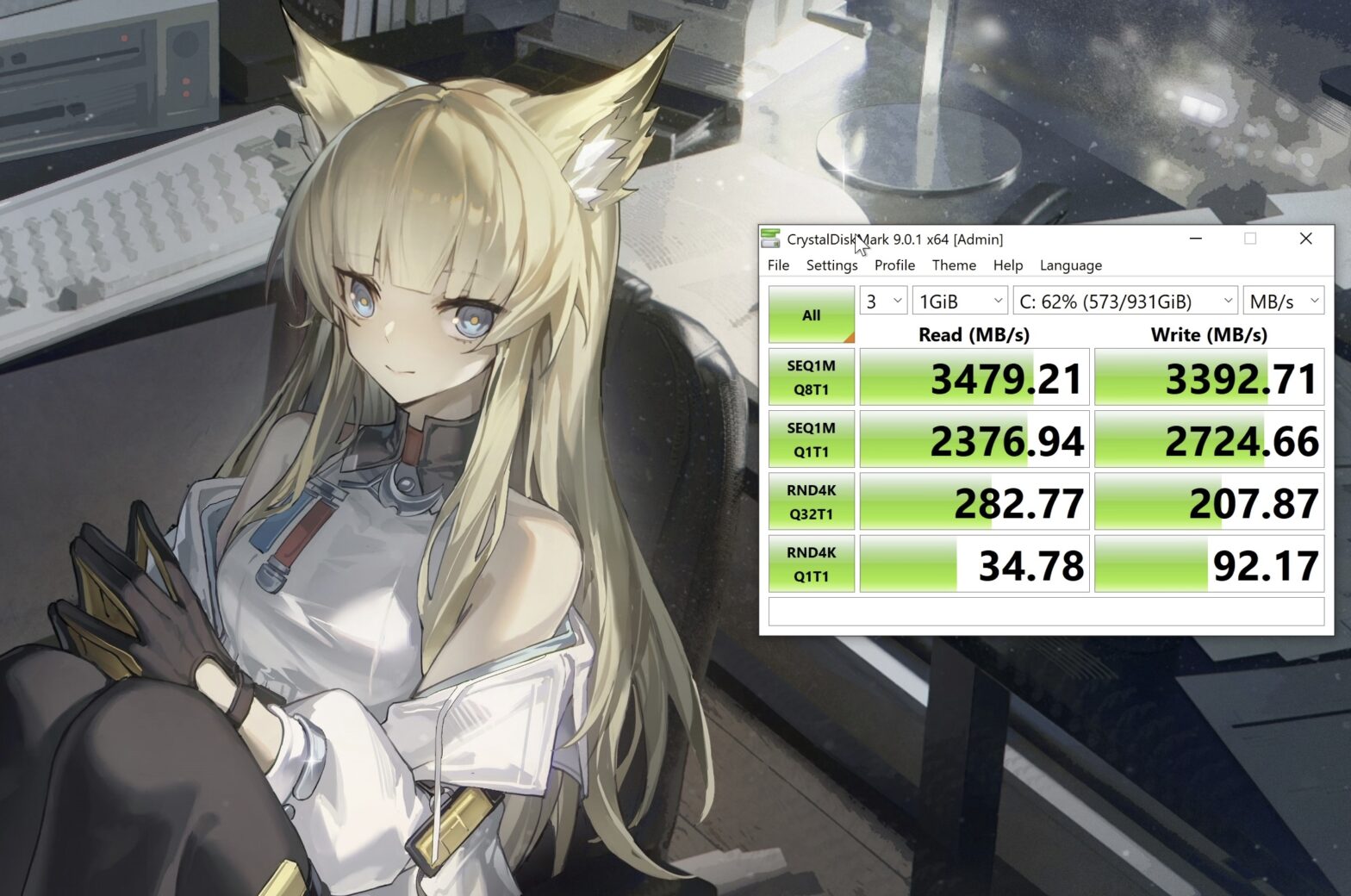
参考自:https://github.com/zhaodice/qemu-anti-detection ,但这个配置会极大影响直通nvme硬盘的4k多线程性能,会从700MB/s跌倒20MB/s,导致游戏加载非常慢。因此研究了一些不影响通过检测的优化,使其恢复到200~300MB/s左右,不再成为瓶颈。
以下是xml配置文件关键段落:
<domain type='kvm' id='62' xmlns:qemu='http://libvirt.org/schemas/domain/qemu/1.0'>
... 略 ...
<features>
<acpi/>
<apic/>
<kvm>
<hidden state='on'/>
</kvm>
<vmport state='off'/>
<smm state='on'/>
<ioapic driver='kvm'/>
</features>
<cpu mode='host-passthrough' check='none' migratable='off'/>
<clock offset='localtime'>
<timer name='rtc' tickpolicy='catchup'/>
<timer name='pit' tickpolicy='delay'/>
<timer name='hpet' present='no'/>
<timer name='kvmclock' present='no'/>
</clock>
<devices>
... 略 ...
<memballoon model='none'/>
</devices>
<qemu:commandline>
<qemu:arg value='-smbios'/>
... 略(请参考最上面的链接) ...
<qemu:arg value='-cpu'/>
<qemu:arg value='host,family=6,model=167,stepping=1,l3-cache=on,model_id=Intel(R) Xeon(R) E-2378 CPU @ 2.60GHz,vmware-cpuid-freq=false,enforce=false,host-phys-bits=true,hypervisor=off,+x2apic,hv-time,hv-relaxed,hv-vapic,hv-spinlocks=0x1fff,hv-vendor-id=GenuineIntel,tsc-frequency=2600000000'/>
</qemu:commandline>
</domain>NVME硬盘4k多线程性能差主要是因为时钟源问题,为通过检测我们无法使用常用的虚拟机高性能时钟源,导致中断性能问题。(是的,pcie直通并非一定没有性能损耗)
其中最为关键的是qemu:arg中的-cpu段落,family=6,model=167,stepping=1,l3-cache=on,model_id=Intel(R) Xeon(R) E-2378 CPU @ 2.60GHz根据实际修改。经过反复测试,必须使用这种方式(libvirt原生配置不完全),同时不能加入migratable=no以打开+invtsc,哪怕加入更多参数修正也会有cpu feature细微差异,导致检测不过。但我们可以设置tsc-frequency=2600000000,强行使用tsc,数值为你的CPU基频(我这里是2.6GHz),睿频不影响。另外这里依然保留了一些hv特性,这对于开启了 Hyper-V 功能(如 VBS/WSL2)的物理机也是存在的,对于Win11机器很常见。